Welcome to Act 2 of our blog series focused on Security Theater where we seek to shed light on the illusion of cloud security. Previously we explained why you should NOT measure success based on compliance. Today we dive into vulnerability findings and how they have become meaningless.
Act 2, Scene 1: Vulnerability Findings Are Meaningless
Okay, maybe they’re not totally meaningless—but they’re not as inherently useful as you might think. In this blog we’ll dive into what we can do to bring value to these security findings.
So, what are findings?
If we go back in time when development was more on-prem and specifically look at application security, findings had to do with static analysis of proprietary code, where the common weakness enumeration (CWE) was used to automate scans and identify patterns in code that could lead to vulnerabilities, such as SQL injection or cross-site scripting.
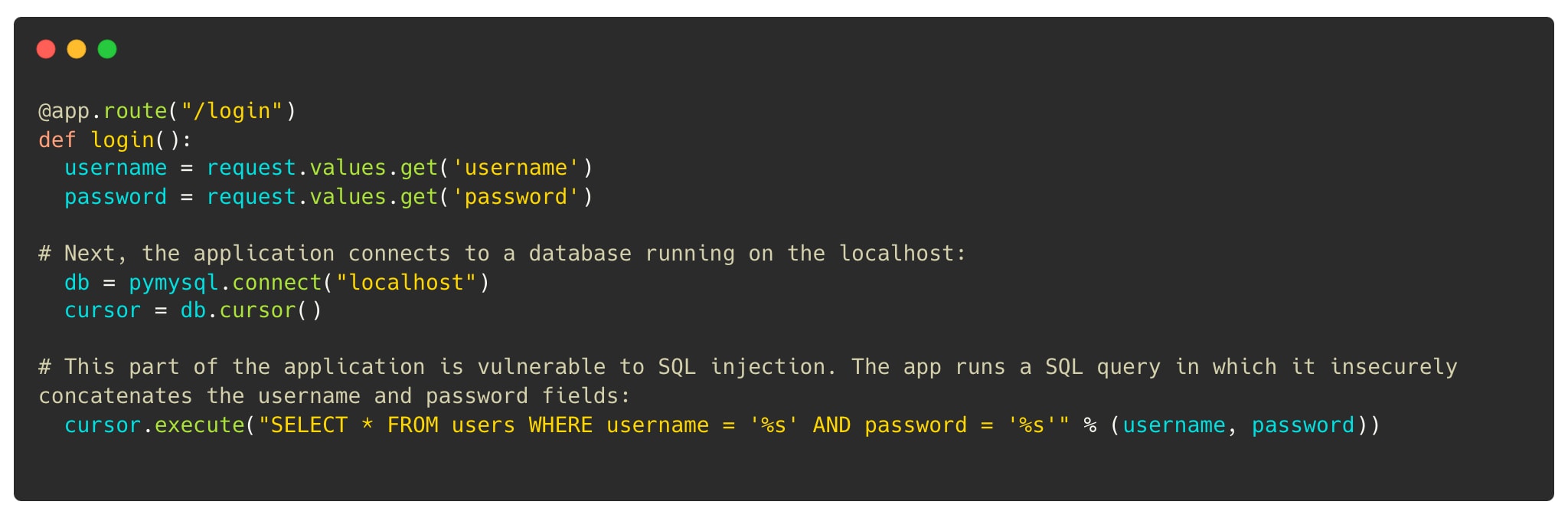
With the shift to the cloud and a prolific adoption of open source code, we see that open-source packages often contain previously identified errors or vulnerabilities, noted by a common vulnerability enumeration (CVE). CVEs are similar to CWEs, with the key difference that CWEs are weaknesses in the code that could lead to a CVE (almost every CVE has underlying CWEs causing them). This distinction is crucial because static analysis on proprietary code can be noisy, finding potential problems that may never manifest, whereas CVEs represent known vulnerabilities in open-source packages.
Today, security findings come from a bevy of different tools. For shift-left or preventative findings, there is static application security testing (SAST), focused on finding potential vulnerabilities (e.g., CWEs) and software composition analysis (SCA), which finds known vulnerabilities (e.g., CVEs) in open-source packages.
These findings, in combination with scanners for misconfigurations in infrastructure as code (IaC) and CI/CD pipelines, are most often used in silos. These tools create an insurmountable volume of findings to assess—some of which may not even be exploitable.
For infrastructure and runtime security, there are even more findings that security teams have to deal with.
Findings Are a Necessary Evil
Shift-left findings are like investigating a robbery—but before it happens with the clues all found in isolation. One investigator sees an open window and another sees a passcode for a safe written on a post-it note, but neither shares that information with the other and no one knows what it means in the context of the entire scene. It’s possible a robber could access through another entrance and valuables were never even in the safe. A robbery might never even take place.
This is the reality when it comes to AppSec findings. When viewed in isolation, they provide little value in understanding real risk. But like a jigsaw puzzle, if you put the pieces together you can view the whole picture.
Act 2, Scene 2: Maximize Efforts with Context
It's a misconception that if a tool is producing more findings, it means better ROI. Context is king when it comes to securing the modern application engineering ecosystem. Let's dive into how we can frame our view to prioritize what matters most.
Contextualize AppSec Scanner Data
On their own, most findings are merely indicators of potential compromise, without necessarily posing any real risk. This can be misleading and result in lots of wasted effort, because when it comes to scanning tools such as SCA or SAST, each can present thousands of possible issues.
The first step to focusing on real risk is determining if these findings are exploitable and if an exploit exists. Achieving deeper context is significantly more challenging but crucial. This involves identifying where the vulnerability resides, whether in a development environment, where it might be less concerning, or in actual production, where the stakes are higher.
Further questions must also be addressed:
- Is the vulnerability connected to sensitive data?
- Is it exposed to the internet?
- How complex would it be to exploit it?
- How many steps are required in the kill chain?
Additionally, the vulnerability's presence alongside a misconfiguration can elevate the risk profile of an application. Only through such detailed analysis do findings begin to have meaningful implications.
Advanced static analysis tools (e.g., SAST) use abstract syntax trees (ASTs) to create a detailed call graph of the code, allowing them to trace every possible path and identify potential mistakes or bad practices. When an SCA tool detects that an imported library in the code is vulnerable, it’s possible though the AST to establish reachability, which means tracing whether external calls can exploit the vulnerability.
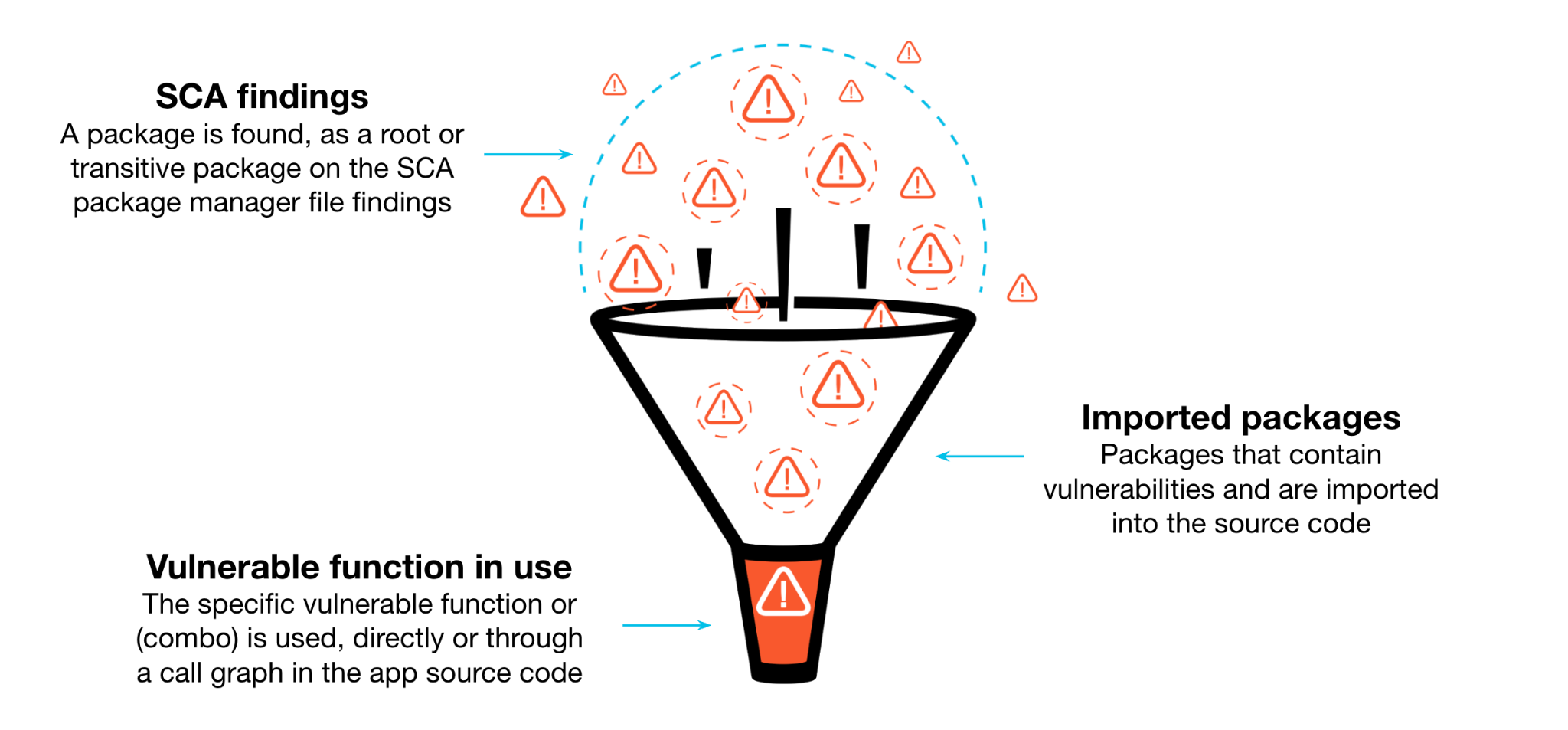
Furthermore, with the shift to IaC, additional context about the deployment environment can be factored in. Analyzing Kubernetes manifests, for example, allows for the scanning of container images referenced in the manifests. Image scanners can uncover vulnerabilities within the containers. If these vulnerabilities coincide with misconfigurations identified by IaC scanning, the risk profile of the application increases significantly.
This approach provides a deeper understanding of potential security risks that enterprises can use to prioritize vulnerabilities and misconfigurations early in the development process.
Adding Runtime Context to AppSec Scanner Data
With the vast number of vulnerability findings, it's inevitable that some are going to reach production. Additionally, new zero day vulnerabilities may be discovered. That’s why adding holistic observability of the application in runtime is important.
It’s possible to leverage context provided by various security tools in combination early by using a preproduction test environment. Even if nothing is currently wrong in the test environment, it’s possible to identify a route from an external API call into a Kubernetes cluster, through a vulnerable and overly provisioned container, to unencrypted data.
For instance, a web application firewall (WAF) can monitor internet traffic, cloud workload protection can detect anomalies in a Kubernetes cluster, and API security can track API calls. Through this integrated context, organizations identify misconfigurations in IaC and ensure resources follow the principle of least privilege, abstracting beyond individual security findings to understand potential attack paths.
This comprehensive view reveals how a vulnerability could lead to a data breach, demonstrating the interconnected nature of security risks.
By recognizing that real threats often result from a combination of misconfigurations, known vulnerabilities and potential unknown issues, organizations can shift the focus from isolated findings to understanding the root causes of genuine risk.
Act 2, Scene 3: The Remedy—Focus on the Root Causes
There’s a huge advantage to understanding if a vulnerability is actually exploitable because it allows you to focus on genuine risk. The key is being able to marry whether the vulnerable package is actually in-use or reachable with runtime context. Teams will then be able to focus on real risk, ideally tracing it back to the source and fixing it in code.
The only way to truly trace issues to their source is by having a single AppSec platform that has a comprehensive view of static scanners, CI/CD environments and runtime context.
Fix in Cloud, Fix Forever in Code
Determining the attack path and the best fix location in the kill chain is crucial for effective cloud security.
While "fix in cloud" sounds straightforward, the specific actions required can vary. Fixing anything in the cloud is a stop-gap solution. Making a small change to a WAF (for example, reconfiguring a WAF to block a Log4shell attack string) might mitigate the attack but leave the underlying vulnerability intact. Similarly, adjusting cloud resource configurations can reduce risk depending on the threat.
Identifying the source of a vulnerability allows for permanent fixes that can address multiple issues simultaneously, efficiently enhancing overall security. With the full application context, you can trace the vulnerabilities to the source and fix them there.
“Fix in code” involves fixing the package within a repository for the running application. Going back to our example, that would mean upgrading the Log4j package in the related package manager file.
Effectively fixing issues forever requires a seamless connection from the cloud back to code, ensuring that redeployments do not reintroduce vulnerabilities or overwrite console-made changes from an IaC perspective.
It's important to create uniform policies for detecting issues both at runtime and early in development to prevent accidental reintroduction of vulnerabilities by others.
Bypass a Ticketing Process Through a PR
Despite the widespread adoption of the term DevSecOps, many security solutions focus primarily on integrating with ticketing systems to address issues observed in runtime. The prevailing workflow often entails security teams identifying a problem, triggering the creation of a ticket within systems like JIRA, and considering their task complete. This fosters a flawed perception that security responsibilities conclude once a ticket is generated and neglects the crucial aspect of tracking the resolution process.
Instead, the effectiveness of security measures should be gauged by the time it takes for an issue to be identified and resolved at its source, not by when a ticket leaves the hands of security teams.
A better strategy for addressing cloud vulnerabilities involves integrating fixes into the DevOps ecosystem. Instead of creating tickets to manually address cloud misconfigurations, it's more efficient to use GitOps principles. When a misconfiguration is found, the best approach is to create a pull request (PR) that modifies the IaC file responsible for provisioning the cloud environment. This PR then goes through the standard review process, allowing those with the necessary context to understand and approve the change. Once approved, the fix is automatically deployed to production.
This method, known as DevSecOps, leverages existing application development mechanisms for making changes to production, streamlining the process and minimizing the need for tickets. While some systemic issues may still require ticketing, adopting a DevSecOps approach can significantly accelerate mean time to remediate (MTTR).
Act 2, Scene 4: Closing Remarks
AppSec findings are NOT useless if you can cut through the noise and focus on the real risk. Don’t waste developers’ time. Maximize efforts by squeezing value out of AppSec findings with proper context.
The simple reality is, AppSec and development teams have different goals and KPIs. By leveraging a platform that enables both teams to streamline application development with easy-to-use integrations for developer tools, organizations can efficiently secure their crown jewels.
The future of AppSec is in a platform approach that provides both shift-left and runtime context to accurately prioritize risk, trace it to its source and fix forever in code.
— End of Act 2 —
Interlude: What's Next?
If you’d like to learn more about how Prisma Cloud approaches AppSec with Code to CloudTM context, join an upcoming shift-left bootcamp.
And check back as we explore more Security Theater. Act 3, Scene 1, coming soon …