What Is Data Movement?
Data movement is the transfer, replication, or ingestion of data between locations within an organization's infrastructure or between cloud datastores. The process of moving data involves technologies like Extract, Transform, Load (ETL), data replication, and change data capture (CDC), which serve to facilitate data migration and warehousing.
Maintaining up-to-date databases, supporting analytics, and ensuring business continuity hinges on data movement. That said, data movement poses security challenges, as uncontrolled data flows can lead to compliance issues and increase the risk of data breaches.
Data Movement Explained
Data movement (sometimes referred to as data flow) is the process of transferring data from one location or system to another – such as between storage locations, databases, servers, or network locations. Data movement plays a part in various information management processes such as data integration, synchronization, backup, migration, and data warehousing.
While copying data from A to B tends to be simple, data movement becomes complicated when you need to manage volume, velocity, and variety:
- Handling large amounts of data (volume)
- Managing the speed at which data is produced and processed (velocity)
- Coping with diverse types of data (variety)
Modern data movement solutions will often incorporate features such as data compression, data validation, scheduling, and error handling to improve efficiency and reliability.
As organizations shift their infrastructure to public cloud providers, data movement is becoming a central consideration. While on-premise environments were typically monolithic and designed around ingesting data into an enterprise data warehouse, cloud environments are highly dispersed and dynamic.
The cloud's elasticity allows businesses to easily spin up new services and scale resources as needed, creating a fluid data landscape where datasets are frequently updated, transformed, or shifted between services. This fluidity presents challenges as organizations must ensure data consistency, integrity, and security across multiple services and platforms.
Related Article: Understanding Data Flow Diagrams
Data Movement and Cloud Data Security
In the context of security, data movement can become an issue when organizations lose visibility and control over sensitive data. Customer records or privileged business information can be duplicated and moved between services, databases, and environments, often leading to the same record existing in multiple data stores and processed by different applications, sometimes in more than one cloud.
This continuous data movement introduces complexities when it comes to protecting sensitive data – particularly in terms of complying with data residency and sovereignty, maintaining segregation between environments, and tracking potential security incidents. For example, when data is regularly moved between databases, the security team might miss an incident wherein the data is moved into unencrypted or publicly-accessible storage.
Cloud data security tools help you map the movement of sensitive data, and identify flows that should trigger immediate responses from security teams. They can also help you prioritize incidents that pose a more serious risk, primarily those involving sensitive data flowing into unauthorized or unmonitored data stores.
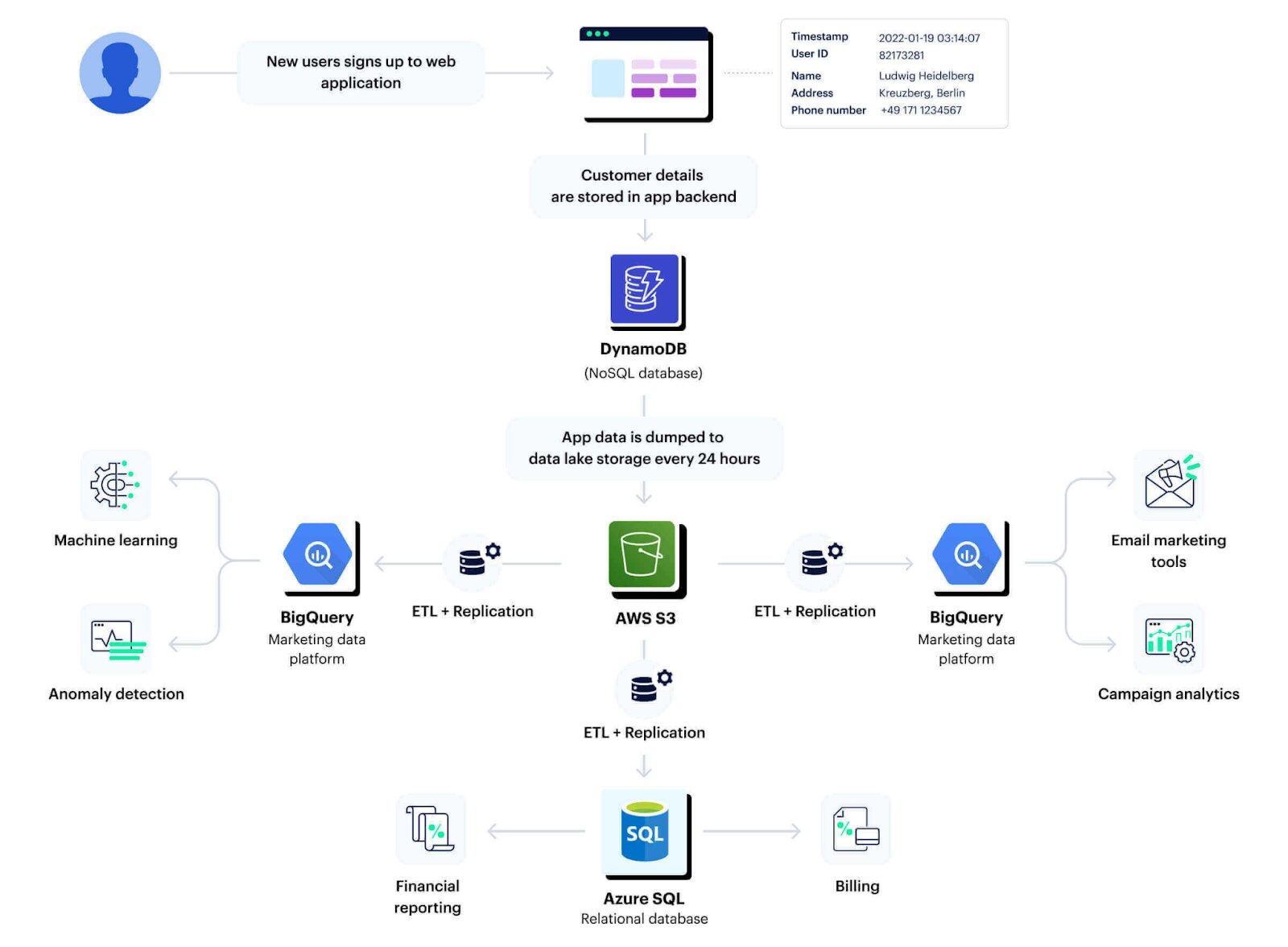
5 Types of Data Movement, With Examples
Data Replication
Copying the same datasets and storing them in different locations. This is typically done for backup and recovery scenarios, to ensure data availability, and to minimize latency in data access across geographically distributed systems. For example: an e-commerce company replicates their inventory database across several regional servers to ensure rapid access for users worldwide.
Data Migration
Moving data from one system or storage location to another, often during system upgrades or when moving data from on-premise servers to cloud environments. Migrations can be complex due to the large volumes of data involved and the need to ensure data integrity during the move. For example: a business migrates its customer data from a legacy on-premise system to a cloud database as a service such as Snowflake.
Data Integration
Combining data from different sources into a unified view. Typically this is done when you try to get a comprehensive view of business operations from disparate business systems or to cleanse and normalize data from a single source. For example: A healthcare provider integrates patient data from multiple systems (scheduling, medical records, billing) to provide a comprehensive patient profile.
Data Streaming
Real-time data movement, where data is continuously generated and processed as a stream – often for monitoring, real-time analytics, or operational use cases. Data streaming services move event-based data that is generated from sources such as applications and sensors to data storage platforms or applications, where it can be analyzed and acted upon immediately. For example: A ride-sharing service like Uber streams location data from drivers' phones to their servers for real-time matching with passengers.
Data Ingestion
Obtaining and importing data into a database (or distributed storage system), either for immediate use or long-term storage. Ingestion can be batch-based or streaming. The process involves loading data from various sources and may include transformation and cleaning of the data to fit the destination storage schema. For example: A financial services firm ingests stock market data from various exchanges into a data lake for further analysis and machine learning.
The Fragmented Landscape of Data Movement Tools
The best evidence for the central role data movement plays in the modern data stack is the highly diverse and complicated tooling landscape that has emerged to support it. Below you will find a small sample of the vendors operating in this space — each category could literally be expanded to dozens of specialized tools, cloud-native solutions, and open source frameworks.
| Data Movement Category | Vendors | Description |
|---|---|---|
| Data Replication | AWS DMS (Amazon) | Homogeneous and heterogeneous database migrations with minimal downtime, used for large-scale migrations and database consolidation. |
| GoldenGate (Oracle) | Real-time data replication and transformation solution, used for high-volume and mission-critical environments. | |
| IBM InfoSphere | Supports high-volume, high-speed data movement and transformation, including complex transformations and metadata management. | |
| Data Migration | AWS Snowball (Amazon) | Physical data transport solution that uses secure appliances to transfer large amounts of data into and out of AWS, useful for limited network bandwidth scenarios. |
| DMS (Amazon) | Supports both homogeneous and heterogeneous migrations and continuous data replication with high availability. | |
| Azure Migration (Microsoft) | Comprehensive suite of tools and resources to simplify, guide, and expedite the migration process. | |
| BigQuery Data Transfer (Google Cloud) | Automates data movement from SaaS applications to Google BigQuery on a scheduled, managed basis. | |
| Informatica | Offers an AI-powered data integration platform to access, integrate, and deliver trusted and timely data. | |
| Talend | Provides a suite of data integration and integrity apps to integrate, clean, manage, and transform data. | |
| Data Integration | Fivetran | Automated data pipeline solutions to load and transform business data in a cloud warehouse. |
| Azure Data Factory (Microsoft) | Data integration service that allows creation, scheduling, and management of data-driven workflows for ingesting data from disparate sources. | |
| AWS Glue (Amazon) | Fully managed ETL service, useful for preparing and loading data for analytics. | |
| Apache Nifi (Open Source) | Supports data routing, transformation, and system mediation logic, good for real-time or batch data pipelines. | |
| DataStage (IBM) | Provides extensive data transformation capabilities for structured and unstructured data. | |
| Google Cloud Data Fusion | Fully managed, cloud-native, data integration service to help users efficiently build and manage ETL/ELT data pipelines. | |
| Data Streaming | Apache Kafka (Open Source) | Distributed event streaming platform, good for high-volume, real-time data streams. |
| Amazon Kinesis (Amazon) | Collects, processes, and analyzes real-time, streaming data, useful for timely insights and reactions. | |
| Google Cloud Pub/Sub | Messaging and ingestion for event-driven systems and streaming analytics. | |
| Azure Stream Analytics (Microsoft) | Real-time analytics on fast moving streams of data from applications and devices. | |
| Confluent | Provides a fully managed Kafka service and stream processing, useful for event-driven applications. | |
| Data Ingestion | Fluentd (Open Source) | Open source data collector for unified logging layer, allowing you to unify data collection and consumption. |
| Logstash (Elastic) | Server-side data processing pipeline that ingests data from multiple sources, transforms it, and then sends it to a "stash" like Elasticsearch. | |
| Kinesis Firehose (AWS) | Fully managed service for delivering real-time streaming data to destinations such as Amazon S3, Redshift, Elasticsearch, and more. | |
| Apache Flink (open source) | Open source stream processing framework for high-performance, reliable, and accurate real-time applications. | |
| Google Cloud Dataflow | Fully managed service for stream and batch processing with equal reliability and expressiveness. |