- 1. Kubernetes Explained
- 2. Kubernetes Architecture
- 3. Nodes: The Foundation
- 4. Clusters
- 5. Pods: The Basic Units of Deployment
- 6. Kubelet
- 7. Services: Networking in Kubernetes
- 8. Volumes: Handling Persistent Storage
- 9. Deployments in Kubernetes
- 10. Kubernetes Automation and Capabilities
- 11. Benefits of Kubernetes
- 12. Kubernetes Vs. Docker
- 13. Kubernetes FAQs
Table of Contents
- Kubernetes Explained
- Kubernetes Architecture
- Nodes: The Foundation
- Clusters
- Pods: The Basic Units of Deployment
- Kubelet
- Services: Networking in Kubernetes
- Volumes: Handling Persistent Storage
- Deployments in Kubernetes
- Kubernetes Automation and Capabilities
- Benefits of Kubernetes
- Kubernetes Vs. Docker
- Kubernetes FAQs
What Is Kubernetes? | Palo Alto Networks
6 min. read
Table of Contents
- Kubernetes Explained
- Kubernetes Architecture
- Nodes: The Foundation
- Clusters
- Pods: The Basic Units of Deployment
- Kubelet
- Services: Networking in Kubernetes
- Volumes: Handling Persistent Storage
- Deployments in Kubernetes
- Kubernetes Automation and Capabilities
- Benefits of Kubernetes
- Kubernetes Vs. Docker
- Kubernetes FAQs
Kubernetes is an extensible, open-source container orchestration platform that manages and automates processes for deploying, running, and scaling containerized services and applications, significantly alleviating the operational burden of container management.
Kubernetes Explained
Kubernetes introduces powerful tools to maximize the effectiveness of containers, cloud-ready apps, and infrastructure as code across cloud environments and operating systems. Also known as “K8s” or “Kube,” it offers development teams incredible scale, flexibility, and speed.
Key to the cloud-native ecosystem, Kubernetes can be configured to manage and monitor on-premises and public, private, and hybrid deployments. It eliminates the manual processes involved in the deployment and scaling of containerized applications by equipping administrators with commands and utilities to deploy, run, and troubleshoot the containers they manage.
Capable of clustering groups of servers hosting Linux containers while allowing administrators to manage those clusters, Kubernetes makes it possible to quickly deploy applications in response to consumer demands — all while limiting hardware resource consumption.
As The New Stack aptly put it:
“A contemporary application, packaged as a set of containers and deployed as microservices, needs an infrastructure robust enough to deal with the demands of clustering and the stress of dynamic orchestration. Such an infrastructure should provide primitives for scheduling, monitoring, upgrading, and relocating containers across hosts. It must treat the underlying compute, storage, and network primitives as a pool of resources. Each containerized workload should be capable of taking advantage of the resources exposed to it, including CPU cores, storage units and networks.”
This is Kubernetes, an infrastructure robust enough.
While Docker excels in containerization, Kubernetes is the undisputed standard in container orchestration. Originally developed by Google, Kubernetes manages clusters of containers, offering advanced features for workload distribution, scaling, and fault tolerance, in addition to abstracting the complexities of underlying infrastructure.
Among surveyed organizations, 96% report using or evaluating Kubernetes, according to the CNCF Annual Survey 2021. Kubernetes is indeed ubiquitous, attesting to its standing with enterprises, platform vendors, cloud providers, and infrastructure companies.
Packed with capabilities to make managing application operations easier, Kubernetes automates rollouts and application updates, as well as handling automated rollback in the event of an error. It can fit containers into fixed resource allocation to maximize the use of resources — and automatically restart, replace, and even kill containers that don’t respond to health check metrics. Kubernetes manages access to storage, networking configuration, and even provides secret and configuration management.
For organizations working CI/CD pipelines, automating code from prototype to production, Kubernetes is cloud-ready and ideal for managing containerized microservices. Even teams unable to run their entire Kubernetes environment take advantage of managed Kubernetes services offered by hyperscaler cloud providers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
As far as the learning curve goes, with the right resources, Kubernetes is just another tool. So let’s look under the hood.
Kubernetes Architecture
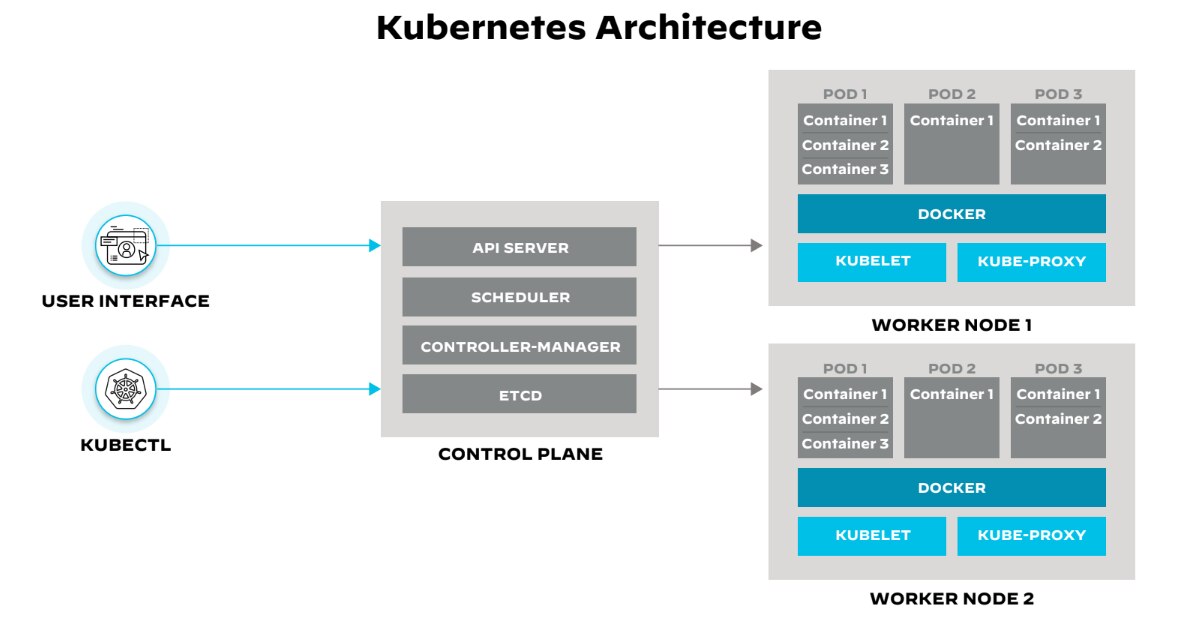
Figure 1: Concepts of a Kubernetes architecture
Kubernetes' architecture is a sophisticated orchestration of components that work in concert to provide a resilient, scalable, and manageable environment for modern applications. Its design encapsulates the complexity of distributed systems, enabling DevOps teams to focus on application-level concerns rather than the intricacies of the underlying infrastructure.
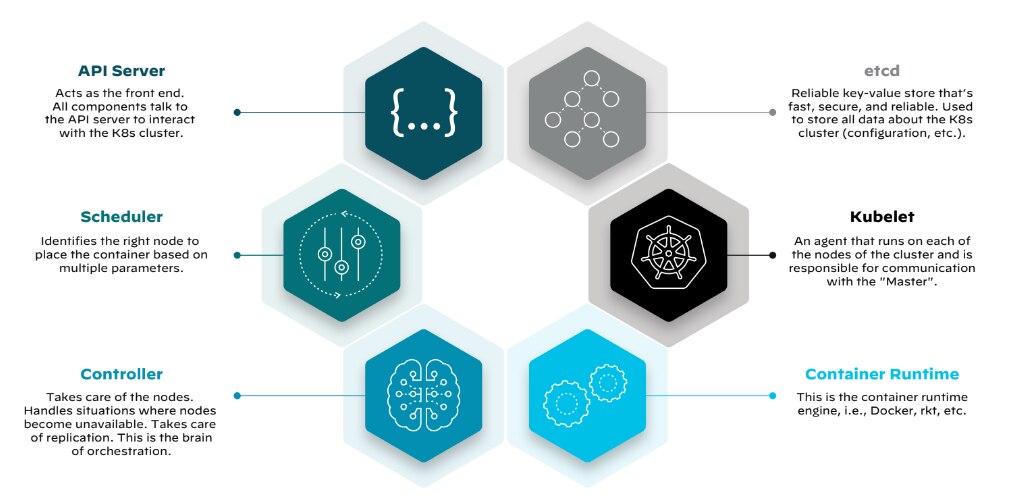
Figure 2: Container orchestration component overview1
Orchestration engines like Kubernetes are complex, consisting of several key technological components that work in unison to manage the lifecycle of containers. By understanding key components, you gain an understanding of how to best utilize containerization technologies.
The Control Plane
At the heart of Kubernetes lies its control plane, the command center for scheduling and managing the application lifecycle. The control plane exposes the Kubernetes API, orchestrates deployments, and directs communication throughout the system. It also monitors container health and manages the cluster, ensuring that container images are readily available from a registry for deployment.
The Kubernetes control plane comprises several components — the etcd, the API server, the scheduler, and the controller-manager.
Etcd
The etcd datastore, developed by CoreOS and later acquired by Red Hat, is a distributed key-value store that holds the cluster's configuration data. It informs the orchestrator's actions to maintain the desired application state, as defined by a declarative policy. This policy outlines the optimal environment for an application, guiding the orchestrator in managing properties like instance count, storage needs, and resource allocation.
API Server
The Kubernetes API server plays a pivotal role, exposing the cluster's capabilities via a RESTful interface. It processes requests, validates them, and updates the state of the cluster based on instructions received. This mechanism allows for dynamic configuration and management of workloads and resources.
Scheduler
The scheduler in Kubernetes assigns workloads to worker nodes based on resource availability and other constraints, such as quality of service and affinity rules. The scheduler ensures that the distribution of workloads remains optimized for the cluster's current state and resource configuration.
Controller-Manager
The controller-manager maintains the desired state of applications. It operates through controllers, control loops that monitor the cluster's shared state and make adjustments to align the current state with the desired state. These controllers ensure the stability of nodes and pods, responding to changes in the cluster's health to maintain operational consistency.
Nodes: The Foundation
Kubernetes has two layers consisting of the master nodes and worker nodes. The master node typically runs the control plane, the brains of the Kubernetes cluster, which is responsible for making decisions about how to schedule and manage workloads. The worker node — also known as worker machine or, simply, node — provides the muscle that runs applications.
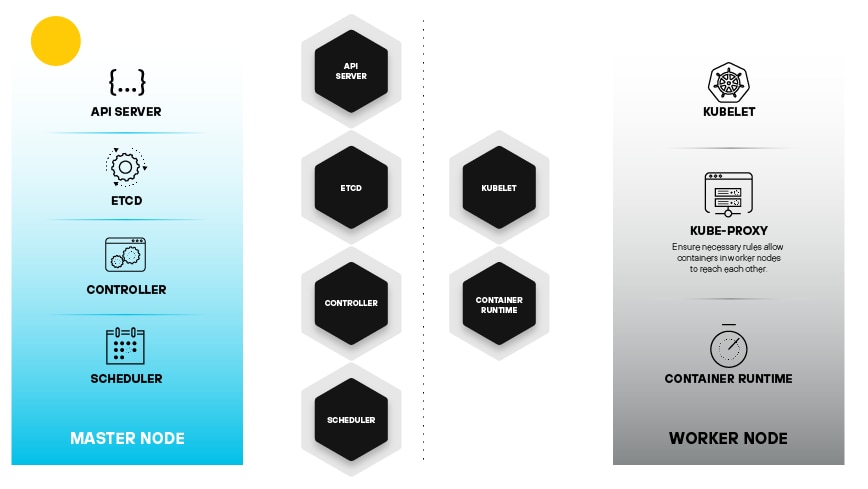
Figure 3: Master and worker node relationship depicting how Kubernetes manages a cluster
The collection of master nodes and worker nodes becomes a cluster. The master node orchestrates the scheduling and scaling of pods, in addition to preserving the cluster's overall state.
The worker nodes are responsible for running pods, managing resources, and communicating with the master, which includes doing work assigned to them by the master node. The worker node(s) serve as the execution environment for the pods.
The control plane ensures efficient management of both the worker nodes and the pods distributed across the cluster.
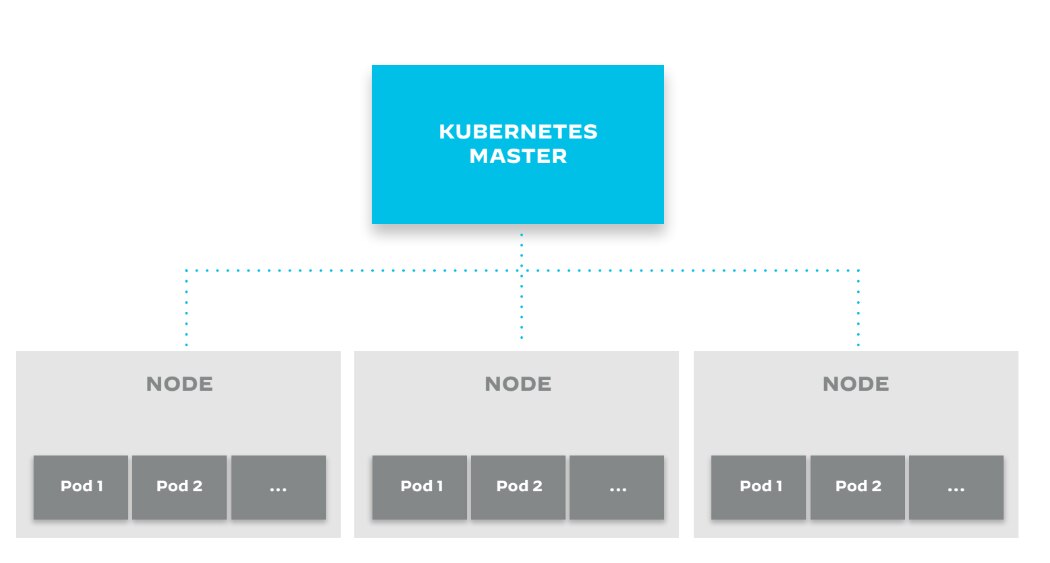
Figure 4: Kubernetes master node, worker node relationship and pod architecture
Kubernetes master, nodes, pods, services, and ingress controller work together to deploy and manage containerized applications. The Kubernetes master schedules pods on nodes. The pods are then started, and the applications are run. The services provide a way to access the pods without having to know their individual IP addresses. The ingress controller routes traffic from the outside world to the services.
Clusters
A cluster is a collection of nodes (bare-metal or virtualized machines) that will host your application pods. Each node in a cluster is managed by the control plane and contains the services necessary to run pods.
Clusters support scalability, reliability, and security with traits such as:
- Pods can move to different nodes as needed.
- The control plane runs on multiple nodes.
- Pods are isolated from each other, and the node processes run in a secure environment.
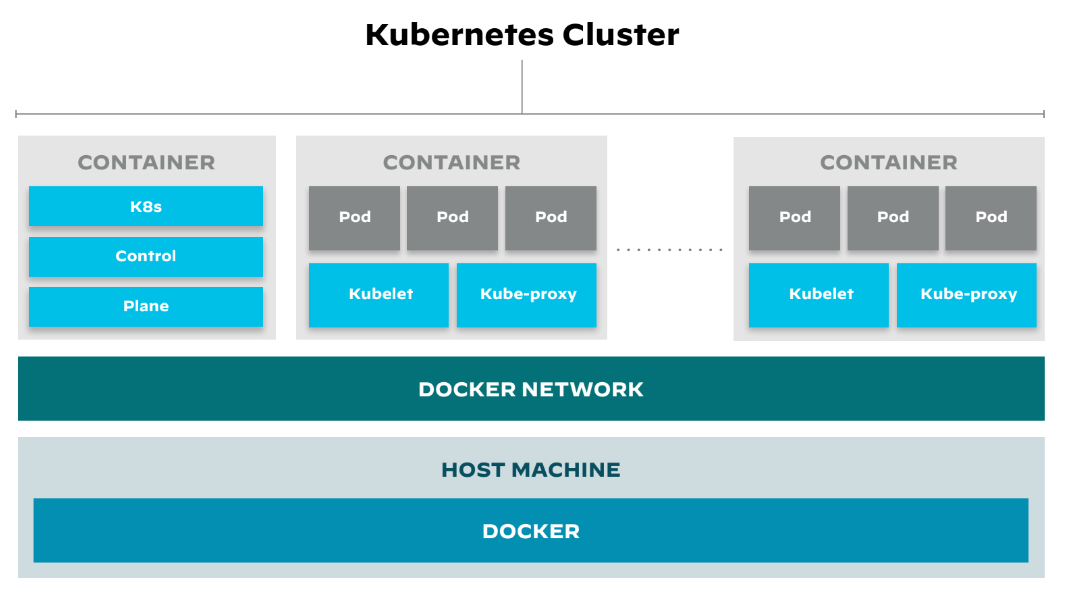
Figure 5: Kubernetes cluster architecture
Kubernetes includes a suite of built-in controllers within the controller-manager, each offering primitives tailored to specific workload types — stateless, stateful, or batch jobs. Developers and operators leverage these primitives to package and deploy applications, leveraging Kubernetes' architecture to achieve high availability, resilience, and scalability in cloud and data center environments.
In addition to ensuring that the current state of the cluster matches the desired state defined by the user, the controller-manager:
- Manages the lifecycle of nodes and pods, handling tasks like node provisioning, replication, and rollout of updates.
- Manages default accounts and API access tokens for new namespaces.
- Operates in a loop, watching the shared state of the cluster through the API server and making changes where necessary.
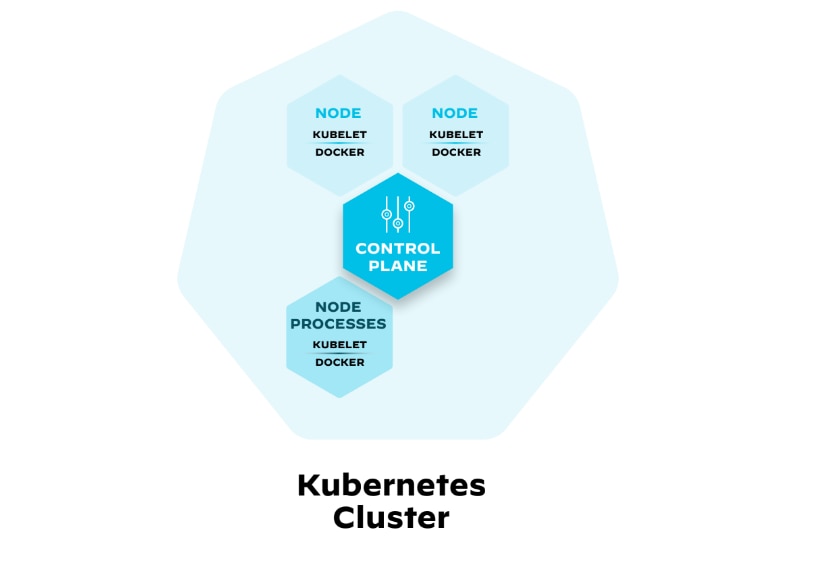
Figure 6: Kubernetes cluster with a few nodes
In the overview of the Kubernetes cluster and how its components work together, figure 6 shows the control plane running on Node1. This is often the case, as the control plane needs to be highly available and reliable.
Namespaces
Kubernetes namespaces partition a cluster’s resources into logically named groups. They provide a way to create virtual clusters within a physical cluster. Each namespace is an isolated, independent environment that contains a unique set of Kubernetes resources, such as pods, services, and replication controllers.
Namespaces are commonly used in large, multitenant Kubernetes environments to provide isolation between teams, projects, or applications. By creating namespaces, you can prevent resources with the same name from conflicting with each other, and you can limit the visibility of resources to specific users or groups.
When you create a namespace, Kubernetes automatically creates a set of default resources in that namespace, including a default service account and a default set of resource quotas. You can customize these defaults and add additional resources as needed.
To use a specific namespace, you can set the namespace context in your Kubernetes configuration or specify the namespace in your kubectl commands.
Pods: The Basic Units of Deployment
The smallest building block of the application workload, the pod represents a single instance of a running process in a cluster. Each pod typically contains a group of containers, all of which share storage and network resources, as well as specifications on how to run the containers. The pod’s contents are co-located and co-scheduled. Additionally, they run in a shared context, meaning that they share the same network namespace, IPC namespace, and storage volume.
Like containers, designed to be created and destroyed quickly, as needed by the application, pods are ephemeral — created, assigned to nodes, and terminated as per the cluster's needs. Kubernetes efficiently manages pods, ensuring that the state of the cluster matches the user's specified state.
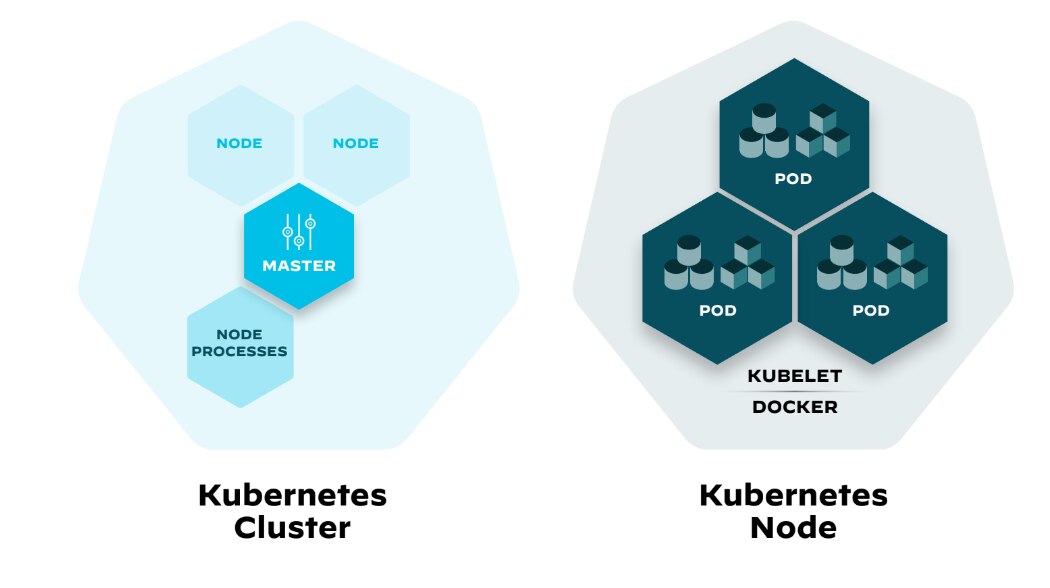
Figure 7: Differences between Kubernetes cluster architecture and Kubernetes node architecture
Kubelet
Kubelet acts as the primary node agent that runs on each node in the Kubernetes cluster. It takes a set of PodSpecs provided through various mechanisms — primarily through the API server — and ensures that the containers described in those PodSpecs are running and healthy. The Kubelet monitors the state of a pod and, if necessary, starts, stops, and restarts containers to try and move the state toward the desired state.
Responsibilities of the Kubelet
- Managing the lifecycle of containers
- Maintaining a reporting on the status of a node and the containers running on it
- Executing container probes to check for liveness and readiness, which are used to determine the health of the containers
- Managing container volumes and network settings
- Ensuring that the container's environment is set up correctly and in accordance with the specifications in the PodSpec
When a Kubelet receives instructions to start a container, it passes these instructions to the container runtime via the CRI. The runtime then takes care of the low-level details of container execution, such as file system management, network isolation, and memory allocation.
In essence, while the Kubelet interacts with both the containers and the node, ensuring that the desired state of the pod is achieved, the container runtime maintains responsibility for running the containers specified by the Kubelet.
Together, these components work in concert to manage the Kubernetes cluster, ensuring that it runs efficiently and resiliently. They represent the control plane's brain, heart, and muscle, orchestrating the complex interactions that keep the cluster functioning smoothly.
Services: Networking in Kubernetes
A service in Kubernetes is an abstraction that defines a logical grouping of pods, as well as a policy providing a way to access pods without having to know their individual IP addresses. This abstraction, or service, enables decoupling, as it allows the frontend of an application to be separated from the backend pods.
Key Features of a Kubernetes Service
- Each service has a stable IP address, which remains constant even as the pods behind it change.
- Services automatically load balance traffic to the pods behind them.
- Kubernetes gives a service its own DNS name, allowing other pods in the cluster to discover and access it easily.
Types of Services
- ClusterIP exposes the service on an internal IP in the cluster, making the service only reachable within the cluster.
- NodePort exposes the service on each Node’s IP at a static port. A ClusterIP service is automatically created, and the NodePort service will route to it.
- LoadBalancer exposes the service externally using a cloud provider’s load balancer.
- ExternalName maps the service to the contents of the externalName field (e.g., foo.bar.example.com), by returning a CNAME record with its value.
Volumes: Handling Persistent Storage
A volume is an abstraction that represents a directory on a disk, which can be mounted into one or more containers as a file system.
Because Kubernetes pods are ephemeral, storage is critical for persisting data, configuration, state, and other uses. Kubernetes volumes provide durable storage across container restarts, node failures, and automatic creation. Volumes ensure that data persists beyond the life of a pod.
When a pod is scheduled to run on a node, Kubernetes can automatically provision a volume and mount it into the pod’s containers.
Types of Volumes
- HostPath mounts a file or directory from the host node’s file system into your pod.
- EmptyDir is a temporary directory that facilitates data sharing between containers within the pod. They persist until the pod's termination.
- PersistentVolumeClaim (PVC) allows a user to request persistent storage without knowing the details of the underlying storage infrastructure.
- ConfigMap and Secret volumes provide a way to pass configuration data or sensitive information to containers running in a pod.
Deployments in Kubernetes
A deployment in Kubernetes provides declarative updates to pods and ReplicaSets. You describe a desired state in a deployment, and the deployment controller changes the actual state to the desired state at a controlled rate.
Deployment Features
- You can easily scale up or down the number of replicas from your deployment.
- Deployments support rolling updates to your application. You can specify the number of pods that can be created above the desired number of pods and the number of pods that can be unavailable during the update.
- If something goes wrong, Kubernetes provides rollback functionality for deployments.
- Deployments ensure that only the specified number of pods are running and available.
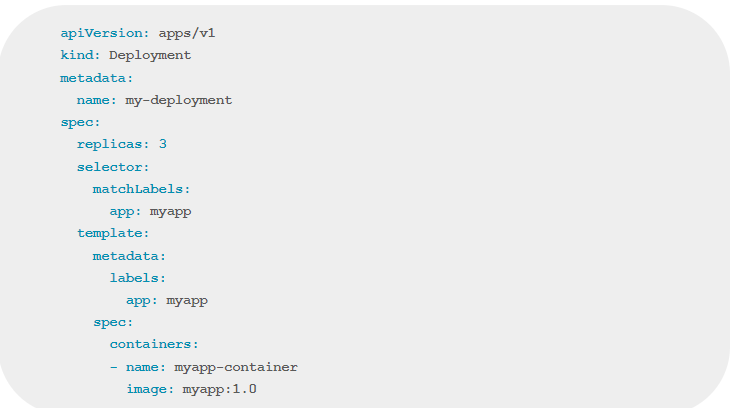
Figure 8: Example of a deployment YAML file
This YAML file creates a deployment named my-deployment that runs three replicas of a container using the myapp:1.0 image.
In figure 8, we see an example of a Service YAML file that exposes the above deployment.

Figure 9: Example of a Service YAML file that exposes the deployment (Figure 8)
This service named my-service exposes the deployments on each node’s IP at a static port in the range 30000-32767.
In Kubernetes, managing applications and controlling their exposure within and outside the cluster is achieved by actively utilizing deployments and services. These essential components help maintain app stability, scale resources, and facilitate secure communication between various components and external users.
Kubernetes Manifest Files
Kubernetes manifest files are an example of infrastructure as code (IaC). Written in JSON or YAML format, they’re used to define the desired state and configuration of various resources within the cluster. Services, volumes, and deployments are all types of resources that can be defined and managed using Kubernetes manifest files.
Kubernetes Automation and Capabilities
Kubernetes is packed with capabilities to make managing application operations easier.
Service Discovery and Load Balancing
As application architectures shift toward microservices, automated registration and scalable routing become crucial. Kubernetes simplifies this by using service discovery and load balancing. It automatically assigns DNS names to services in a private cluster directory, allowing services to locate and communicate with each other. Kubernetes supports various load balancing types, including round-robin, IP hash, and session affinity, distributing traffic evenly and efficiently across multiple replicas. Internal and external load balancing ensure seamless communication within the cluster and proper traffic distribution for incoming requests.
Storage Orchestration
Kubernetes storage orchestration manages storage resources in a cluster, ensuring availability and accessibility for applications and services. It abstracts various storage options like NAS, block storage, object storage, and cloud services, simplifying management and provisioning. Kubernetes enables dynamic provisioning, resizing, and deletion of storage resources without disrupting applications, supporting its dynamic and automated approach to resource management.
Automatic Bin Packaging
Kubernetes automatic bin packaging schedules containers onto nodes, maximizing resource utilization and minimizing waste. Based on pod resource requirements, node capacity, affinity rules, and priority, its scheduling algorithm optimizes pod distribution across the cluster, enhancing application availability and reliability by ensuring sufficient resources and automatic rescheduling in case of node failures.
Kubernetes’ Self-Healing Features
Kubernetes ensures smooth application operation and availability through various self-healing features:
- By managing replica sets, Kubernetes maintains the desired number of running application instances, automatically replacing failed pods and scaling when needed.
- Built-in health checks monitor pod health, and Kubernetes replaces unhealthy pods automatically.
- Users can specify how applications should recover from failures, defining liveness/readiness probes, pod restart policies, and advanced scheduling rules like pod affinity/anti-affinity.
- Kubernetes supports rolling updates, incrementally replacing old application versions with new ones without downtime, ensuring successful deployment before updating the next pod.
- Built-in monitoring continuously assesses node and pod health, taking corrective actions like restarting pods or rescheduling them to healthy nodes when necessary.
These self-healing features allow DevOps teams to maintain high application availability even in the face of failures or issues.
Secret and Configuration Management
In Kubernetes-based environments, managing secrets and configurations programmatically is crucial. Kubernetes offers centralized, secure storage and management of sensitive information and configurations through its built-in secrets and ConfigMap APIs. Secrets store encrypted data like passwords and API keys, while ConfigMaps manage application configurations. Both can be accessed by pods via environment variables or mounted volumes. The secrets API supports automatic rotation and specific types, with updates propagated to relevant pods. Kubernetes also supports third-party tools like Helm for managing complex configurations and dependencies.
Benefits of Kubernetes
While Kubernetes’ learning curve can intimidate some, the benefits for larger teams with complex applications can be significant.
Increase Development Velocity
Containerization has forever changed the way developers pull system components together to create working applications. Because they’re modular, agile, and support streamlined automation, they greatly reduce the friction of managing full virtual machines, while also being easily distributed, elastic, and platform agnostic to a large degree.
Kubernetes amplifies the value of containers by creating an orchestration platform that unlocks the benefits of containers at-scale.
The rise of DevOps demands rapid development and deployment of large-scale, highly available applications. Containerization revolutionizes this process with modular, agile, and automated components, reducing the friction of managing full virtual machines while being easily distributed, elastic, and platform agnostic.
Deploying Applications Anywhere at Any Scale
Kubernetes can deploy on any number of operating systems including varieties of Linux, macOS, and Windows. Utilities can enable Kubernetes to run on a local computer for testing or daily development work. Teams can also manage Kubernetes through Kubernetes distributions, which come precompiled and preconfigured with tools and utilities. Popular Kubernetes distributions include Rancher, Red Hat OpenShift, and VMware Tanzu.
Public cloud hyperscalers also offer managed Kubernetes platforms, such as:
- Amazon Elastic Kubernetes service (EKS)
- Microsoft Azure Kubernetes service (AKS)
- Google Kubernetes Engine (GKE)
- Oracle Container Engine for Kubernetes (OKE)
Whether teams prefer to run Kubernetes on-premises, private cloud, hybrid cloud, or public cloud, a distribution and deployment model exists to support the architecture.
Kubernetes Vs. Docker
Those unfamiliar with container technology will often hear Docker and Kubernetes referenced together and may ask themselves — What’s the difference between these two container technologies? While Kubernetes and Docker are equally popular and often used together, they have different purposes and functions.
Docker is a container engine, or containerization platform, that allows developers to package and deploy applications in a standardized format called a Docker container. Docker provides an easy-to-use interface for creating, managing, and running containers.
Kubernetes is a container orchestration platform that automates the deployment, scaling, and management of containerized applications across a cluster of nodes. Kubernetes provides a way to manage multiple containers and their interdependencies, and it can automatically scale applications up or down based on-demand.
Docker creates and packages individual containers, while Kubernetes manages and orchestrates multiple containers across a distributed infrastructure.
While Kubernetes can work with containers created using other containerization technologies, Docker is one of the most popular containerization platforms and is often used with Kubernetes. Docker provides a standard format for containerization and Kubernetes provides the tools to manage and orchestrate those containers at scale.
Kubernetes FAQs
YAML (short for "Yet Another Markup Language") is a human-readable data serialization format. It’s designed to be easily understood and written by people while being easily parsed and processed by machines. YAML uses simple punctuation marks and indentation to represent data structures like lists, dictionaries, and key-value pairs.
YAML files are commonly used for configuration files, data exchange between languages with different data structures, and as a more readable alternative to JSON and XML. In the context of container orchestration and DevOps, YAML files are frequently used to define configurations, resource definitions, and deployment manifests for platforms like Kubernetes, Docker Compose, and Ansible.
Infrastructure as code is a practice of managing and provisioning infrastructure resources (such as networks, virtual machines, and storage) using machine-readable definition files, typically in a version-controlled system. IaC enables developers and operators to automate the setup, configuration, and management of infrastructure components, making it easier to maintain and replicate environments across different stages of the software development lifecycle.
Examples of IaC in the Context of Kubernetes
Kubernetes manifests: YAML or JSON files that define the desired state of Kubernetes resources, such as deployments, services, and config maps.
Tools like Helm, Kustomize, and Jsonnet: Enable templating and packaging of Kubernetes manifests to simplify the management of complex environments.
External IaC tools like Terraform and CloudFormation: Manage Kubernetes clusters and underlying cloud resources, such as Virtual Private Clouds (VPCs), security groups, and IAM roles.
JSON (JavaScript Object Notation) is a lightweight data interchange format that’s easy for humans to read and write — while being easy for machines to parse and generate. JSON files use a language-independent text format that relies on conventions familiar to programmers of the C family of languages, including C, C++, C#, Java, JavaScript, Perl, and Python.
In the context of container orchestration, JSON files are often used to store and exchange configuration data, define resources, and describe the desired state of the system. Orchestration platforms like Kubernetes, Docker Swarm, and Apache Mesos rely on JSON (or formats like YAML, which are easily converted to JSON) to manage the deployment, scaling, and management of containerized applications.
JSON File Use Cases
Configuration files: JSON files can be used to store configuration data for containerized applications and orchestration platforms, such as environment variables, network settings, and resource limits.
Manifests and templates: Orchestration platforms often use JSON or YAML files to define resources like deployments, services, and ingresses in Kubernetes or services and tasks in Docker Swarm. These files describe the desired state of the resources and the orchestration platform ensures that the actual state matches the desired state.
API communication: JSON is a common format for exchanging data between APIs, including the APIs provided by orchestration platforms. When interacting with orchestration platform APIs, developers can use JSON files to send requests and receive responses, making it easier to automate tasks and integrate with other tools.
Storage and retrieval of metadata: JSON files can be used to store metadata about containerized applications, such as version information, dependency data, and build details. This metadata can be used by the orchestration platform to manage the deployment and updates of containerized applications.
Custom resource definitions (CRDs): In Kubernetes, JSON or YAML files can be used to define custom resources that extend the platform's functionality. These custom resources can be managed by the Kubernetes API, just like built-in resources.
Jsonnet is an open-source data templating language for app and tool developers. An extension of JSON, it allows developers to define reusable components, reduce duplication, and generate complex configurations more efficiently. Jsonnet simplifies the creation and management of configuration files, particularly in scenarios where configurations share a lot of common elements or require dynamic generation based on input parameters.
In the context of container orchestration, Jsonnet can simplify the management of complex resource definitions and configurations for platforms like Kubernetes, Docker Swarm, or Apache Mesos. It’s particularly useful when dealing with large-scale deployments or environments where configurations need customization to address specific requirements.
Jsonnet Use Cases
Template-based resource definitions: Jsonnet allows you to define templates for orchestration resources, such as Kubernetes deployments, services, and ingresses. These templates can be parameterized and reused across different environments, reducing duplication and making it easier to manage complex configurations.
Conditional logic and parameterization: Jsonnet supports conditional logic, loops, and parameterization, enabling developers to generate dynamic configurations based on input parameters or environmental factors. This can be useful for managing different configurations for development, staging, and production environments.
Hierarchical configuration management: Jsonnet supports hierarchical configuration management, allowing developers to define common configuration elements and then extend or override them for specific use cases or environments. This can help maintain consistency across configurations while still allowing customization where needed.
Integration with CI/CD pipelines: Jsonnet can be integrated into CI/CD pipelines to automatically generate resource definitions and configurations as part of the build and deployment process. This can help ensure that configurations are always up to date and in sync with the application code.
Extensibility and reuse: Jsonnet's extensibility allows for the creation of libraries and reusable components, enabling developers to share and reuse common configuration elements across multiple projects and teams.
By using Jsonnet in container orchestration, developers can simplify the management of complex configurations, reduce duplication, and improve consistency across environments. This can lead to more efficient development and deployment processes and make it easier to maintain and scale containerized applications in orchestrated environments.
YAML or JSON files that define the desired state of Kubernetes resources, such as deployments, services, and config maps. These can include security configurations like network policies, RBAC policies, and pod security policies.
Helm Charts are prepackaged, versioned, and sharable Kubernetes applications or resources that can be easily deployed, managed, and updated. Often referred to as the package manager for Kubernetes, Helm simplifies the process of managing complex Kubernetes applications by providing a way to define, package, and distribute Kubernetes resources in a structured and reusable manner.
Helm Charts are essentially a collection of YAML files that describe the desired state, configuration, and dependencies of Kubernetes resources, such as deployments, services, configmaps, and more. They’re organized in a specific directory structure.
Main components of Helm Charts
Chart.yaml contains metadata about the chart, such as its name, version, description, and any optional information like keywords, maintainers, and sources.
values.yaml defines the default configuration values for the chart, which can be overridden by users during deployment. These values are used as placeholders in the chart's templates and are replaced with actual values during the deployment process.
templates/ is a directory that contains Kubernetes manifest templates, which are YAML files with embedded Go template language elements. These templates define the structure and configuration of the Kubernetes resources that will be created when the chart is deployed. The Go templating language allows you to use variables, loops, conditionals, and functions to make the charts more dynamic and customizable.
charts/ (optional) is a directory that contains the packaged versions of the chart's dependencies, which are included if they are not available in the Helm repository.
helpers.tpl (optional) contains snippets of reusable Go template code, which can be included in the templates to avoid repetition and improve maintainability.
Kustomize is a standalone tool for Kubernetes that allows you to customize raw, template-free YAML files for multiple purposes, without using any additional templating languages or complex scripting. It’s specifically designed to work natively with Kubernetes configuration files, making it easy to manage and maintain application configurations across different environments, such as development, staging, and production. Kustomize introduces a few key concepts:
Base is a directory containing the original, unmodified Kubernetes manifests for an application or set of related resources.
Overlay is a directory containing one or more Kustomize files that describe how to modify a base to suit a specific environment or use case.
Kustomize file (kustomization.yaml or kustomization.yml) is the central configuration file used by Kustomize to describe the desired modifications to the base resources.
Kustomize files are essentially configuration files that define how to modify the base Kubernetes YAML manifests. Used by Kustomize to describe the desired modifications to the base resources, they typically include instructions like adding common labels or annotations, changing environment-specific configurations, and generating or patching secrets and config maps.
Common Directives Used in Kustomize Files
resources: List of files or directories to include as base resources.
patches: List of patch files that modify the base resources.
configMapGenerator: Generates a ConfigMap from a file, literal, or directory.
secretGenerator: Generates a Secret from a file, literal, or command.
commonLabels: Adds common labels to all resources and selectors.
commonAnnotations: Adds common annotations to all resources.
Policies in the context of Kubernetes security refer to a set of rules and guidelines that help enforce security requirements. They can be applied to various aspects of Kubernetes, such as network traffic, pod creation, and access control.
Examples of Policies
Network Policies: Control and manage network traffic within a Kubernetes cluster, allowing you to define rules for ingress and egress traffic between different pods and namespaces.
Pod Security Policies: Define a set of conditions that a pod must meet before being accepted into the system, helping to prevent the deployment of insecure or non-compliant workloads.
Role-Based Access Control (RBAC) Policies: Control access to Kubernetes resources by defining roles and permissions for users and service accounts, ensuring that they have the minimum necessary privileges.
Policies are specific security rules and guidelines used to enforce security requirements within a Kubernetes environment, while IaC is a broader practice for managing and provisioning infrastructure resources using code. Both can be used together to improve security, consistency, and automation within your Kubernetes environment.
Using IaC, you can define and manage security configurations like network policies, firewall rules, and access controls as part of your infrastructure definitions. For example, you can include Kubernetes network policies, ingress and egress configurations, and role-based access control (RBAC) policies in your Kubernetes manifests, which are then managed as infrastructure as code.
Tools like Terraform, CloudFormation, and Kubernetes manifests allow you to manage infrastructure resources and security configurations in a consistent and automated manner. By incorporating security measures into your IaC definitions, you can improve the overall security of your container and Kubernetes environment and ensure adherence to best practices and compliance requirements.
Policy as code (PaC) involves encoding and managing infrastructure policies, compliance, and security rules as code within a version-controlled system. PaC allows organizations to automate the enforcement and auditing of their policies, ensuring that their infrastructure is built and maintained according to the required standards. By integrating these policies into the policy as code process or as part of the infrastructure build, organizations can ensure that their tooling aligns with the necessary standards and best practices.
Provenance for containers is the capability to verify the authenticity of an image (or other code) via a method like a digital signature.
Referring to the origin and history of a software container, provenance is useful in understanding the source, dependencies, and changes made to a container over time, ensuring its integrity and trustworthiness.
Key aspects of Provenance
Source: The origin of the container image, including the base image, source code, and the person or organization responsible for creating it.
Dependencies: The libraries, frameworks, and tools used within the container, which could impact its functionality and security.
Metadata: Information about the container, such as creation date, version, and labels, that can help in tracking and managing it.
Changes: A history of modifications made to the container, including updates, patches, and bug fixes, which can impact its performance and security.
Trust: Ensuring that the container and its contents can be trusted, typically through techniques like digital signatures and verification.
Resource Query Language (RQL) is a query language designed to search and filter resources in cloud environments. RQL policies are a set of rules or conditions defined using RQL syntax to evaluate and enforce security, compliance, or best-practice requirements across cloud resources.
RQL policies are typically used with cloud security platforms, like Prisma Cloud, to monitor and manage cloud resources more effectively. By defining RQL policies, security and infrastructure teams can identify misconfigurations, compliance violations, or potential security risks in their cloud environments. This helps organizations maintain a secure and compliant cloud infrastructure by continuously monitoring and analyzing cloud resources based on the defined RQL policies.
A syscall (system call) audit in host OS container security refers to the process of monitoring, logging, and analyzing system calls made by processes running within containers on a host operating system. System calls are the interface between an application and the kernel, allowing applications to request resources or services from the operating system, such as file access, network connections, or process management.
In the context of container security, syscall auditing is crucial for detecting and preventing potential security breaches or malicious activities. By monitoring the system calls made by containerized processes, security teams can gain insights into the behavior of applications running within containers and identify any abnormal or suspicious activities.
Syscall auditing can help:
Detect unauthorized access or privilege escalation attempts by monitoring system calls related to file access, user management, or process control.
Identify the use of insecure or deprecated system calls, which might expose the container or the host system to potential security risks.
Recognize attempts to exploit known vulnerabilities or perform malicious activities within the container, such as launching a remote shell or exfiltrating data.
Tools like auditd, eBPF, or container runtime security solutions can be used to implement syscall auditing in host OS container security. By integrating syscall auditing into the overall container security strategy, organizations can enhance their security posture and minimize the risks associated with containerized applications.
A key-value store is a type of database that employs a simple data model, where data is stored and retrieved using unique keys associated with corresponding values. The model allows for efficient and straightforward data management, particularly for scenarios with large amounts of simple data records. Key-value stores are known for their high performance, scalability, and ease of use, making them ideal for applications requiring quick data access or real-time processing.
In the Kubernetes environment, a key-value store is used as the backend for storing and managing the cluster's state and configuration data. This datastore, also known as the etcd cluster, helps maintain the high availability and consistency of Kubernetes clusters.
1 Container orchestration components will vary slightly among vendors.
2 We expand content on Kubernetes in this section to convey concepts that generally apply to other orchestrators.